
This article mainly discusses the algorithm involved in the process of HashMap insertion and capacity expansion. For a brief introduction of HashMap, see this article “Determination of the composition and size of HashMap”.
1. Access process of elements
Using Java8 as a reference, the process for inserting a HashMap element is as follows:
- Check whether the current capacity is empty. If yes (the initial capacity value is not set), expand the capacity to 16.
- To obtainkeythehashCodeforhashCodeThe subscripts of the elements are calculated.
- Judge by the subscripthashCollisions, if none, go straight into the bucket.
- If a collision occurs, compare the two keys to see if they are the same. If they are the same, they are overwritten. If they are different, they are inserted in a linked list at the end. (Tail insertion method).
- If the length of the list after insertion exceeds the threshold (TREEIFY_THRESHOLD = 8), the list is transformed into a red-black tree.
- After successful insertion, if the number of elements reaches the threshold (size = capacity x threshold), expand the capacity (maximum capacity: 1<<31).
- After the expansion is successful, the subscripts of the elements are recalculated.
2. A hash function
To help you understand the recalculation process after expansion, let’s take a look at two versions of the hash function
-
Java7
/** * Retrieve object hash code and applies a supplemental hash function to the * result hash, which defends against poor quality hash functions. This is * critical because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. * Retrieves the hash code of the object and applies a supplementary hash function to the resulting hash, which can defend against poor quality hash functions. * This is important because hashMaps use a 2nth power of length hash table, otherwise they would encounter collisions with low-order undifferentiated hash codes. * Note: The null key always maps to the hash of 0, so the index is 0. * / final int hash(Object k) { int h = hashSeed;//hashSeed is a hash mask value that is applied to the hash code of the key to make hash collisions harder to find if (0! = h && kinstanceof String) {// If the hash mask is initialized and the key is a String return sun.misc.Hashing.stringHash32((String) k);// This method is explained below } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). // This function ensures that there are a certain number of collisions (about 8 under the default load factor) for a hash code that is only separated by a constant multiple of each bit position. h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } Copy the codeBy looking at the source code,stringHash32((String) k) this method is finally called getStringHash32()
public int getStringHash32(String string) { return string.hash32(); } Copy the codeClick on this hash32();
/** * Calculates a 32-bit hash value for this string. * Calculates a 32-bit hash value for this string@return a 32-bit hash value for this string. */ int hash32(a) { int h = hash32; if (0 == h) { // harmless data race on hash32 here. h = sun.misc.Hashing.murmur3_32(HASHING_SEED, value, 0, value.length); // The code is not readable because it is confused // ensure result is not zero to avoid recalcing h = (0! = h) ? h :1; hash32 = h; } return h; } Copy the codeSo, for example, let’s write down the calculation of this method;
Suppose I now put an element whose key value is “code”; Since the mask is not initialized, we skip calling stringHash32(); > h ^= k.hashcode ();
By calculation, the *hashCode()* of "*code*" is 3059181 (see this article for how to calculate hashCode: [the hashCode method "in the String source] (https://blog.csdn.net/qicha3705/article/details/119393053)). ```java h ^= k.hashCode(); h = h ^ k.hashCode(); = 0 ^ 3059181; // The mask is not initialized, so h=0 = 0000 0000 ^ 10 1110 1010 1101 1110 1101; // Convert to binary = 10 1110 1010 1101 1110 1101; //^ (xor: 1, 0) = 3059181; 1 xOR, a total of 1 disturbance processing. ** > h ^= (h >>> 20) ^ (h >>> 12); ** > h ^= (h >>> 20); ```java h ^= (h >>> 20) ^ (h >>> 12); h = h ^ ((h >>> 20) ^ (h >>> 12)); = 3059181 ^ ((3059181 > > > 20) ^ (3059181 > > > 12)); = 10 1110 1010 1101 1110 1101 ^ ((10 1110 1010 1101 1110 1101>>> 20) ^ (10 1110 1010 1101 1110 1101>>> 12)); = 10 1110 1010 1101 1110 1101 ^ (10 ^ 10 1110 1010); = 10 1110 1010 1101 1110 1101 ^ 10 1110 1000; = 10 1110 1010 1111 0000 0101; = 3059461; Two xOR, two shifts, a total of four disturbancesCopy the codeStep 3: > return h ^ (h >>> 7) ^ (h >>> 4);
```java h ^ (h >>> 7) ^ (h >>> 4) = 3059461 ^ (3059461 >>> 7) ^ (3059461 >>> 4); = 10 1110 1010 1111 0000 0101 ^ (10 1110 1010 1111 0000 0101>>> 7) ^ (10 1110 1010 1111 0000 0101>>> 4); = 10 1110 1010 1111 0000 0101 ^ 10 1110 1111 0010 0101 1011 ^ 10 1100 0100 0101 1111 0101; = 00 0000 0101 1101 0101 1110 ^ 10 1100 0100 0101 1111 0101; = 10 1100 0001 1000 1010 1011; = 2889899; 2 xOR,2 shifts, a total of 4 disturbance processing. Let's make statistics of these three steps: Steps | exclusive or (b) | displacement disturbance in total (times) | -- -- -- -- -- -- -- - | -- - | | - h ^ = k.h ashCode () | | | 0 1 h ^ = (h > > > 20) ^ (h > > > 12) | 2 | 2 | 4 h ^ (h > > > 7) ^ (h > > > 4) | 2 | 2 | add up the number of 4 * hash function () * a total of nine disturbance after processing, calculation process is more complex. ** * Java public V put(K key, V value) {... int hash = hash(key); int i = indexFor(hash, table.length); . } /** * Returns index for hash code h. */ static int indexFor(int h, int h) int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; Return h & (length-1); // The length of the HashMap must be 2 to the nonzero power. } Java index = hash(key) & (length-1); = 2889899 & (16-1); = 2889899 & 15; = 10 1100 0001 1000 1010 1011 & 1111; = 1011; = 11; Elements with key* "*code*" will be stored in a bucket with index 11.Copy the code-
The hash function for a HashMap in Java8 is much simpler and goes straight to the code
/** * Computes key.hashCode() and spreads (XORs) higher bits of hash * to lower. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don't benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations Because of table bounds. * computes key.hashcode () and propagates the high hash (XOR) to the low hash. * Because this table uses a power of 2 masking, hash groups that change only the number of bits above the current masking will always collide. * (Known examples include collections of Float keys that hold consecutive integers in small tables). * Therefore, we apply a transformation that disperses the high effect downward. There is a tradeoff between speed, practicality, and the quality of bit propagation. * because many common hash set is already a reasonable distribution of (so do not benefit from the transmission), and because we use the tree to deal with the collision county, * we just in the cheapest way of shifting the XOR some bits, in order to reduce system losses, * and into the top bits, the influence of the boundaries of otherwise due to the table, will never be used to index calculation. * / static final int hash(Object key) { int h; return (key == null)?0 : (h = key.hashCode()) ^ (h >>> 16); } Copy the codeAssuming that the key of the put element is still “code”, here’s how it works:
int h = key.hashCode(); = 3059181; = 10 1110 1010 1101 1110 1101; int hash = h ^ (h >>> 16); = 10 1110 1010 1101 1110 1101 ^ (10 1110 1010 1101 1110 1101 >>> 16); = 10 1110 1010 1101 1110 1101 ^ 10 1110; = 10 1110 1010 1101 1100 0011; = 3059139; 1Exclusive or,1Sub shifts, total2Subdisturbance treatmentCopy the codeCalculate the subscript:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null)/ / this line. }Copy the codeThe calculation steps are the same as for *indexFor()* in Java7, so they will not be repeated
Let’s compare two versions of the hash function:
The version number Xor (times) Shift (times) Disturbance in total java7 5 4 9 java8 1 2 2
As you can see, in the java8 implementation, the algorithm optimized for high-order operations requires only two perturbations, compared to nine perturbations in java7, and the java8 hash function is still more efficient in terms of efficiency. As for why java8 has reduced the number of disturbances, it is speculated that it may be because the discrete distribution is too long and the improvement is not obvious, or it is reduced for the sake of efficiency.
3. Source code interpretation
-
Java7
First, you insert an element by calling the put method
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for The key, the old * value is replaced. * associates the specified value with the specified key in the map. * If the map previously contained a key map, then the old value will be replaced */ public V put(K key, V value) { if (table == EMPTY_TABLE) {// If the table is empty, initialize the capacity first inflateTable(threshold); } if (key == null) return putForNullKey(value);// If the key is null, the key is inserted into the bucket with the index 0 int hash = hash(key);// Perturb the key hashCode int i = indexFor(hash, table.length);// Calculate the index based on the hash value calculated by perturbation // Iterate over the table to see if the key already exists. If so, override the old value and return the old value for(Entry<K,V> e = table[i]; e ! =null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;//modCount Number of times this hash table has been modified addEntry(hash, key, value, i);// Insert a new node if the inserted element does not exist in the table return null; } Copy the codeNext, enter the addEntry() method
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if Appropriate. * Adds a new entry with the specified key, value, and hash code to the specified bucket. * The responsibility of this method is to adjust the size of the table when appropriate. * / void addEntry(int hash, K key, V value, int bucketIndex) { // If the number of elements exceeds the threshold and other elements already exist in the bucket of the inserted element, perform capacity expansion if ((size >= threshold) && (null! = table[bucketIndex])) { resize(2 * table.length);// Double the original size, with a maximum capacity of integer.max_value hash = (null! = key) ? hash(key) :0; // Perturb the hashCode of the new element key bucketIndex = indexFor(hash, table.length);// Calculate the index based on the hash value calculated by perturbation } // Create a new node createEntry(hash, key, value, bucketIndex); } Copy the codeYou can see that we’re expanding first and then inserting new elements
createEntry()
/** * Like addEntry except that this version is used when creating entries * as part of Map construction or "Pseudo-construction" (cloning, * deserialization). This version needn't worry about resizing the table. This version is only used when creating entries as part of a map build or "fake build" (cloning, deserialization). * There is no need to worry about the size of the adjustment table in this version. * / void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex];// Get the header element of the list according to the subscript table[bucketIndex] = new Entry<>(hash, key, value, e);// Create a new node, using the header element of the original list as the next reference of the new node size++;// Number of elements +1 } Copy the codeHow does resize() perform capacity expansion
/** * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically When the * number of keys in this map reaches its threshold. * Rewashes the contents of the map into a new array with a larger capacity. * This method is automatically called when the number of keys in the map reaches a threshold. * If current capacity is MAXIMUM_CAPACITY, this method does not * resize the map, MAX_VALUE. * If the current capacity is MAXIMUM_CAPACITY, this method does not resize the map, * instead sets the threshold to integer.max_value. * This has the effect of preventing future calls. * / void resize(int newCapacity) { Entry[] oldTable = table;// Save the old array int oldCapacity = oldTable.length;// Save the length of the old array if (oldCapacity == MAXIMUM_CAPACITY) {// If the old array length reaches 1 << 30 threshold = Integer.MAX_VALUE;// Set the threshold to 1 << 31-1 and the capacity expansion will not be triggered return; } Entry[] newTable = new Entry[newCapacity];// Create a new array that is twice as long as the old array // Move the elements from the old table to the new table and recalculate the subscripts of the elements from the old table transfer(newTable, initHashSeedAsNeeded(newCapacity));// Note: At this time, the subscripts of newly added elements are not recalculated together. Instead, the subscripts are calculated separately after the expansion is successful, and the new elements are added to the container after the calculation is successful table = newTable;// Replace the container with the new table threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);// Calculate the threshold for the next capacity expansion } Copy the codeThe initHashSeedAsNeeded() function initializes the hash mask value, which is not shown here
/** * Transfers all entries from current table to newTable. * Transfers all elements from the old table to the newTable. * / void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length;// Save the length of the new table // Iterate over the table and recalculate the subscripts for (Entry<K,V> e : table) { while(null! = e) { Entry<K,V> next = e.next;if (rehash) { e.hash = null == e.key ? 0 : hash(e.key);// Perturb the key hashCode } int i = indexFor(e.hash, newCapacity);// Calculate the index based on the hash value calculated by perturbation e.next = newTable[i]; newTable[i] = e; e = next;// Put the header in the list.}}}Copy the codeTo summarize the process of inserting elements in java7:
-
Java8

Again, let’s look at the PUT method first
```java
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
* 将指定的值与该地图中指定的键相关联。
* 如果该地图以前包含一个键的映射,那么旧的值将被替换。
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
```
可以看到这里调用了*hash(key)*方法,我们后面再分析这个函数,点进去*putVal*()方法
```java
/**
* Implements Map.put and related methods.
* 实现了Map.put和相关方法
* @param hash key的hash值
* @param key 要存储的key
* @param value 要存储的value
* @param onlyIfAbsent 如果当前位置已存在一个值,是否替换,false是替换,true是不替换
* @param evict 表是否在创建模式,如果为false,则表是在创建模式
* @return previous value, or null if none 返回旧值,没有则返回空
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//检查表是否为空,如果为空就初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//调用resize()进行扩容,Java7中初始化和扩容是两个函数,Java8中整和为一个函数了
//计算下标,判断该下标的桶中是否有元素,如果没有则直接放入桶中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//放入桶中的头元素
else {
Node<K,V> e; K k;
//如果有元素并且发生了hash碰撞,判断两个元素的key是否相等,相等则覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果key不相等,判断桶中的元素是否为红黑树节点,如果是则插入到树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果以上都不成立,则证明该桶中是一个链表,遍历该链表,找到链表中的尾部元素并插入到尾部
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//p.next = null代表此元素是尾部元素
p.next = newNode(hash, key, value, null);//插入到尾部
//判断当前链表的元素是否超过要转换为红黑树的阈值 (节点数超过8并且数组长度超过64就要转换为红黑树)
if (binCount >= TREEIFY_THRESHOLD - 1) //此处-1只是为了树化做缓冲,并不代表元素个数达到8-1=7就进行树化,真正判断树化的方法在下一行
treeifyBin(tab, hash);//判断是否满足树化条件,满足则转成红黑树储存
break;
}
//遍历链表,看链表中是否存在hash和key与要插入进来的元素相同,如果相同则跳出循环;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;//此处跳出表示链表中发生了hash冲突,并且两个元素的key相同
p = e;
}
}
//链表中存在相同的key,直接覆盖旧值并返回旧值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;//覆盖旧值
afterNodeAccess(e);//访问后回调
return oldValue;//返回旧值
}
}
++modCount;//表的操作记录+1
//判断当前的元素个数是否达到阈值,达到则扩容;可以看到这里是插入成功后才扩容,而Java7中是先扩容后插入
if (++size > threshold)
resize();
afterNodeInsertion(evict); //插入后回调
return null;
}
```
*扩容操作*
```java
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
* 初始化或加倍表的大小。如果为空,则按照字段阈值中的初始容量目标进行分配。
* 否则,因为我们使用的是2次方扩展,所以每个bin中的元素必须保持在相同的索引上,
* 或者在新表中以2的幂的偏移量移动。
* @return the table 返回正在使用的表
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//如果原表容量>0(表示初始化过,Java8中扩容和初始化为一个方法)
if (oldCap > 0) {
//如果原容量已经达到最大容量了,无法进行扩容,直接返回
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;//把阈值设置为int最大值,会导致后续无法触发扩容操作
return oldTab;//返回旧表
}
//如果旧容量扩容后的值大小大于等于默认值并且小于最大值,把容量扩充为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; //设置新容量为旧容量的两倍
}
/**
* 从构造方法我们可以知道
* 如果没有指定initialCapacity, 则不会给threshold赋值, 该值被初始化为0
* 如果指定了initialCapacity, 该值被初始化成离initialCapacity的最小的2的次幂
* 这里这种情况指的是原table为空,并且在初始化的时候指定了容量,
* 则用threshold作为table的实际大小
*/
else if (oldThr > 0) // 初始容量被置于阈值中
newCap = oldThr;
//构造方法中没有指定容量,则使用默认值(此情况一般出现于调用空构造方法场景)
else {
newCap = DEFAULT_INITIAL_CAPACITY;//新容量为1<<16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//计算新的阈值
}
// 计算指定了initialCapacity情况下的新的 threshold
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
/**
* 从以上操作我们知道, 初始化HashMap时,
* 如果构造函数没有指定initialCapacity, 则table大小为16
* 如果构造函数指定了initialCapacity, 则table大小为threshold,
* 即大于指定initialCapacity的最小的2的整数次幂
* 从下面开始, 初始化table或者扩容, 实际上都是通过新建一个table来完成
*/
@SuppressWarnings({"rawtypes","unchecked"})
/**
* 此处的执行逻辑类似于Java7的transfer()函数,实质上是通过旧表和新表做数据迁移
* 只是在Java8中设计到红黑树节点的变换,所以逻辑比Java7复杂
*/
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//建立一个新表
table = newTab;//当前使用的表改为新表
if (oldTab != null) {//如果旧表不为空
for (int j = 0; j < oldCap; ++j) {//遍历旧表
Node<K,V> e;
if ((e = oldTab[j]) != null) {
/**
* 这里注意, table中存放的只是Node的引用,
* 这里将oldTab[j]=null只是清除旧表的引用,
* 但是真正的node节点还在, 只是现在由e指向它,
*/
oldTab[j] = null;
//下标为j的旧桶中只有一个节点,直接放入新桶中
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;//计算在新表中的下标
//桶中为红黑树,则对树进行拆分,对树的操作后续会专门出一篇文章讲解
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//桶中为链表,对旧链表一分为二,即需要转移的链表和不需要转移的链表
else {
Node<K,V> loHead = null, loTail = null; //保存不需要转移链表的头节点和尾节点
Node<K,V> hiHead = null, hiTail = null;//保存需要转移链表的头节点和尾节点
Node<K,V> next;
//遍历该桶
do {
next = e.next;
//找出拆分后仍处在原下标桶中的节点,保存在不需要转移的链表中
if ((e.hash & oldCap) == 0) {//e的hash值相对于旧容量的最高位是否是0,为0表示此节点不需要被转移,即新下标 = 旧下标
if (loTail == null)//不需要转移链表的尾节点为空代表检索刚开始,此时的e是桶中的第一个元素
loHead = e;//把e保存为不需要转移链表的头节点
else//代表此时正在被检索的节点不是原桶中的头元素
loTail.next = e;//把当前正在检索的节点作为不需要转移链表尾节点的next节点,即当前被检索的节点作为新的尾节点(这里可以看出执行的是尾插法)
loTail = e; //把e记录为不需要转移链表的尾节点
}
//找出拆开后不在原下标桶中的节点,保存在需要转移的链表中
else {//e的hash值相对于旧容量的最高位是否是1,为1表示此节点需要被转移,即新下标=旧下标+旧容量
if (hiTail == null)//需要转移链表的尾节点为空代表检索刚开始,此时的e是桶中的第一个元素
hiHead = e;//把e保存为需要转移链表的头节点
else//代表此时正在被检索的节点不是原桶中的头元素
hiTail.next = e;//把当前正在检索的节点作为需要转移链表尾节点的next节点,即当前被检索的节点作为新的尾节点
hiTail = e; //把e记录为需要转移链表的尾节点
}
} while ((e = next) != null);//一直检索到原桶中的尾元素,结束循环(尾节点没有next节点)
//这里做了进一步的验证,判断分出来的不需要转移链表是否有尾节点
if (loTail != null) {//为空则表示原桶中的所有节点都需要转移
loTail.next = null;//如果有则把尾节点的next引用置空(因为此时链表中的尾节点不代表是原桶中的尾节点,如果不置空可能会导致链表连接错误)
newTab[j] = loHead;//把不需要转移链表放入新表中,位置为原下标
}
//同上,判断分出来的需要转移链表是否有尾节点
if (hiTail != null) {//为空则表示原桶中的所有节点都不需要转移
hiTail.next = null;//如果有则把尾节点的next引用置空(防止错误引用链)
newTab[j + oldCap] = hiHead;//把需要转移链表放入新表中,位置为原下标+旧容量
}
}
}
}
}
return newTab;//返回新表
}
```
*java8*的*resize*()函数有点复杂,我们拆分为两个问题来看
- **为什么*java8*不需要调用*hash*函数重新计算下标**
下标计算公式为 *index = (n - 1) & hash*;
假设扩容前的长度为16,*key*的*hash值*为xxxx 1011,则扩容前元素的下标计算过程为:
```java
int index =(n - 1) & hash;
= (16 - 1) & xxxx 1011
= 15 & xxxx 1011
= 1111 & xxxx 1011
= 1011
= 11
```
因为与(&)计算原理为必须对位的两个值都是1才为1,所以这里实际参与计算的只有hash值的低4位;
由于*HashMap*的容量位2的次方,所以容量-1可以转化为N个相连的数位1;
在发生扩容后,容量增长为原来的两倍 - 32,此时参与重新计算下标的值为(n-1)31,转化为二进制为 1 1111;
```java
int index =(n - 1) & hash;
= (32 - 1) & xxxx 1011
= 31 & xxxx 1011
= 1 1111 & xxxx 1011
```
我们暂停在这一步,画图看一下两次运算结构的差别

可以看到扩容前hash值实际参与运算的数位为4,扩容后实际参与运算的数位为5;由于扩容前后hash值是不变的,所以运算结果的后4位也不会发生改变;
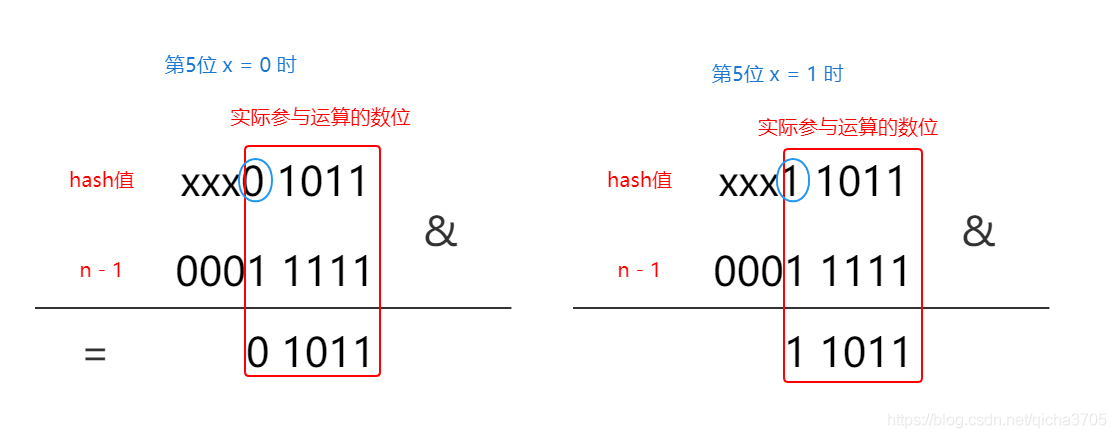
Copy the codeWhen the x value of the highest bit after expansion is 0, that is, the x value of the fifth bit is 0, the final operation result is the same as the original one, that is, the index of this node in the new table is the same as the original one, and belongs to the linked list that does not need to be migrated. When the x value corresponding to the fifth bit is 1, the last 4 of the final operation result is the same as the original, except that the fifth bit changes to 1, and the subscript value changes, which belongs to the linked list to be migrated. It can be interpreted as:
```java 11011 = 1011 + 1 0000 ; New subscript = old subscript + old capacity; *** summary ** : * - When x=0 (i.e. E.ash & oldCap == 0), the position of this node in the new table does not need to be moved. - When x=1 (e.ash & oldCap == 1), the position of this node in the new table is moved by new index = old index + old capacity.Copy the codeNow you know why we need to split the list in two.
- java8How to split the data in the original bucket into two linked lists (with and without the transfer list)Let’s see how it breaks down the data:
Suppose a data link is found in a bucket of the old table subscript n that needs to be split
First we retrieve the first element in n, data1, assuming that data1 needs to be migrated
Continue to retrieve data1 next node data2, after calculation, datA2 also needs to be migrated;
 First we retrieve the first element in n, data1, assuming that data1 needs to be migrated
First we retrieve the first element in n, data1, assuming that data1 needs to be migrated Continue to retrieve data1 next node data2, after calculation, datA2 also needs to be migrated;
Continue to retrieve data1 next node data2, after calculation, datA2 also needs to be migrated;== Note that the next reference to data1 is still unchanged, pointing to data2; == == Is ready to retrieve the next node of data1, which is not the data1 in the list to be migrated, but the data1 in the original bucket; = =






* to summarize the process of inserting elements in java8: *! [insert picture description here] (HTTP: / / https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/8b0d5df94c9a430693057bf3565f47b1~tplv-k3u1fbpfcp-zoom-1.im age)Copy the code4. Discussion of some problems
-
Why do we needhash()Function, instead of using it directlykeythehashcodeWe just compute the subscripts
Here’s an example:
So let’s say we have A HashMap of size 16, and now I put two elements A and B into it; The key of element A is keyA, and element B is keyB; After calculation, keyA’s HashCode is XXXX 1001,keyB’s hashCode is XXXX 1001,x may be 1 or 0; Assume that the hashcode of keyA and keyB has the same lowest bit but different highest bit; Now we compute the subscript h & length-1 of these two elements by taking mod;
```java indexA = keyA.hashCode() & (16-1); = xxxx 1001 & (16-1); = xxxx 1001 & 15; = xxxx 1001 & 1111; = 1001; = 9; ``` ```java indexB = keyB.hashCode() & (16-1); = xxxx 1001 & (16-1); = xxxx 1001 & 15; = xxxx 1001 & 1111; = 1001; = 9; By calculation, it can be found that when the capacity is 16, the final results are equal by subscript the two *key* with different highest bits and the same lowest bits; If there are many such keys, a large number of elements may be put into the same bucket, resulting in a high possibility of hash collisions. In order to avoid this situation, before the subscript calculation, we need to perturbate the *hashCode* of *key* by *hash* function, so that the high level can also participate in the calculation, making the distribution more hash, and finally achieve the purpose of reducing hash conflicts.Copy the code-
Why did java8 head plug to tail plug
The first interpolation:
Flow chart:

To insert a new node into the bucket with the subscript 3, the value isdata4; Step 1: Remove the head node – from the original bucketdata1, using the original head node as the new nodedata4Next node; Step 2: Replace the new node with the original head node; As shown in figure:

* The implementation in the code is: Java /** * Transfers all entries from current table to newTable. */ void transfer(Entry[] Transfers, boolean rehash) { int newCapacity = newTable.length; For (Entry<K,V> e: table) {// loop through each index in the table while(null! = e) {// Start loop Entry<K,V> next = e.ext; // Save the next node of this node for the next loop if (rehash) {// Whether to recalculate the hash value e.hash = null == e.kay? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); // recalculate the subscript e.ext = newTable[I]; NewTable [I] = e; // Insert the new subscript list into the head node e = next; / / remove the save the next node, ready to begin the next cycle}}} ` ` ` * * * * * end plug method: flow chart of * > * * :! [insert picture description here] (HTTP: / / https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/70965c97e4244e71b657d80aee53954d~tplv-k3u1fbpfcp-zoom-1.im age)Copy the codeTo insert a new node into the bucket with the subscript 3, the value isdata4; Step 1: Remove the head node – from the original bucketdata1To finddata1The next nodedata2; Step 2: Repeat step 1 and continue to look for and finddata2If the next node is empty, this element is at the end of the list, and the search stops. Step 3: Insert the new node as the next node at the end of the list; As shown in figure:

Java final V putVal(int hash, K key, V value, Boolean onlyIfAbsent, Boolean evict) {... for (int binCount = 0; ; ++binCount) {// if ((e = p.ext) == null) {// if (e = p.ext) == null) {// if (e = p.ext) = newNode(hash, key, value, null); If (binCount >= treeify_threshold-1) // -1 for 1st treeifyBin(TAB, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key ! = null && key.equals(k)))) break; p = e; }... } *java8* is more efficient when the overhead of finding a node is much lower than that of finding a tail node, so why risk the overhead of switching to a tail interpolation? ** * Example 1: ** > Assume that *HashMap* has an initial capacity of 2. Now ** put*3 pieces of data into the container.Copy the code==PS: This is mainly for the display of migration data. There is a gap between the element expansion time and the actual situation == PUT (5, data), PUT (7, data), put(3, data);




Java Entry<K,V> next = e.ext; Java Entry<K,V> next = e.ext; // Save the next node of the node being migrated! [please add images to describe] (https://img-blog.csdnimg.cn/a2d998f174544ccaaec64a9102aca4b1.png?x-oss-process=image/watermark, type_ZmFuZ3poZW 5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FpY2hhMzcwNQ==,size_16,color_FFFFFF,t_70) int i = indexFor(e.hash, newCapacity); // Calculate the new subscript of the migrated node. E.ext = newTable[I]; NewTable [I] = e; // Set the first node in the new bucket as the next node of the migration node. // e = next; Example 2: ** > Let's assume that the initial capacity of *HashMap* is 2. Now let's *put*3 pieces of data () into the container, put(5, data), put(7, data), put(3, data); The table is migrated by thread A and thread B simultaneously. Suppose thread A suspends until it has just expanded the array; Thread A releases the time slice and thread B starts executing until the migration is complete. The current structure is:! [insert picture description here] (HTTP: / / https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/0a716437eb9e4c7cad82a535438a505d~tplv-k3u1fbpfcp-zoom-1.im Age) Since thread B has finished executing, according to the Java memory model, the nodes in the table are now the most recent values in main memory, which is: 7.next = 3 3.next = NULL, 5.next = NULL.Copy the codeAt this point, switch back to thread A and continue execution at the point in time when thread A is suspended:



Conclusion:
-
Why did Java7 and before use headplugs
Because the authors of Java7 believe that the most recently inserted element has the maximum probability of being accessed the next time (the time-locality principle of caching), placing the most recently inserted data in the head node can improve the efficiency of lookup and reduce the number of queries.
-
Since head interpolation has linked list loop problems, why didn’t it take until Java8 to use tail interpolation instead of head interpolation
Only in the case of concurrency, the problem of link list forming can occur in the head interpolation method; HashMap is not thread safe with multiple threads, so it took until Java8 to fix the bug.
-
Since Java8 doesn’t have a linked list loop problem, does that mean you can use hashmaps in Java8 for multithreading
Even if the linked list loop problem is solved, it doesn’t mean that HashMap doesn’t have other concurrency problems in multithreaded situations; For example, the value of put in the first second is not the value of put in the next second. Because none of the operations are locked, they are not thread-safe; To ensure thread security, use ConcurrentHashMap.
-
How does HashMap resolve Hash conflicts

-
Why are wrapper classes such as String and Integer in HashMap appropriate for key keys

-
If the key in a HashMap is of type Object, what methods should be implemented?

-
Why does a HashMap have the following characteristics: all key-values are allowed to be empty, threads are unsafe, order is not guaranteed, and storage locations change over time
